publications
publications by categories in reversed chronological order.
2023
- BMVCDeepliteRT: Computer Vision at the EdgeAshfaq, Saad, Hoffman, Alexander, Mitra, Saptarshi, Sah, Sudhakar, AskariHemmat, MohammadHossein, and Saboori, Ehsan2023
The proliferation of edge devices has unlocked unprecedented opportunities for deep learning model deployment in computer vision applications. However, these complex models require considerable power, memory and compute resources that are typically not available on edge platforms. Ultra low-bit quantization presents an attractive solution to this problem by scaling down the model weights and activations from 32-bit to less than 8-bit. We implement highly optimized ultra low-bit convolution operators for ARM-based targets that outperform existing methods by up to 4.34x. Our operator is implemented within Deeplite Runtime (DeepliteRT), an end-to-end solution for the compilation, tuning, and inference of ultra low-bit models on ARM devices. Compiler passes in DeepliteRT automatically convert a fake-quantized model in full precision to a compact ultra low-bit representation, easing the process of quantized model deployment on commodity hardware. We analyze the performance of DeepliteRT on classification and detection models against optimized 32-bit floating-point, 8-bit integer, and 2-bit baselines, achieving significant speedups of up to 2.20x, 2.33x and 2.17x, respectively.
@misc{ashfaq2023deeplitert, title = {DeepliteRT: Computer Vision at the Edge}, author = {Ashfaq, Saad and Hoffman, Alexander and Mitra, Saptarshi and Sah, Sudhakar and AskariHemmat, MohammadHossein and Saboori, Ehsan}, year = {2023}, eprint = {2309.10878}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, } - ICCVWYOLOBench: Benchmarking Efficient Object Detectors on Embedded SystemsLazarevich, Ivan, Grimaldi, Matteo, Kumar, Ravish, Mitra, Saptarshi, Khan, Shahrukh, and Sah, SudhakarIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops Oct 2023
We present YOLOBench, a benchmark comprised of 550+ YOLO-based object detection models on 4 different datasets and 4 different embedded hardware platforms (x86 CPU, ARM CPU, Nvidia GPU, NPU). We collect accuracy and latency numbers for a variety of YOLO-based one-stage detectors at different model scales by performing a fair, controlled comparison of these detectors with a fixed training environment (code and training hyperparameters). Pareto-optimality analysis of the collected data reveals that, if modern detection heads and training techniques are incorporated into the learning process, multiple architectures of the YOLO series achieve a good accuracy-latency trade-off, including older models like YOLOv3 and YOLOv4. We also evaluate training-free accuracy estimators used in neural architecture search on YOLOBench and demonstrate that, while most state-of-the-art zero-cost accuracy estimators are outperformed by a simple baseline like MAC count, some of them can be effectively used to predict Pareto-optimal detection models. We showcase that by using a zero-cost proxy to identify a YOLO architecture competitive against a state-of-the-art YOLOv8 model on a Raspberry Pi 4 CPU. The code and data are available.
@inproceedings{Lazarevich_2023_ICCV, author = {Lazarevich, Ivan and Grimaldi, Matteo and Kumar, Ravish and Mitra, Saptarshi and Khan, Shahrukh and Sah, Sudhakar}, title = {YOLOBench: Benchmarking Efficient Object Detectors on Embedded Systems}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops}, month = oct, year = {2023}, pages = {1169-1178} } - CVPRWDeepGEMM: Accelerated Ultra Low-Precision Inference on CPU Architectures Using Lookup TablesGanji, Darshan C., Ashfaq, Saad, Saboori, Ehsan, Sah, Sudhakar, Mitra, Saptarshi, AskariHemmat, MohammadHossein, Hoffman, Alexander, Hassanien, Ahmed, and Léonardon, MathieuIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops Jun 2023
A lot of recent progress has been made in ultra low-bit quantization, promising significant improvements in latency, memory footprint and energy consumption on edge devices. Quantization methods such as Learned Step Size Quantization can achieve model accuracy that is comparable to full-precision floating-point baselines even with sub-byte quantization. However, it is extremely challenging to deploy these ultra low-bit quantized models on mainstream CPU devices because commodity SIMD (Single Instruction, Multiple Data) hardware typically supports no less than 8-bit precision. To overcome this limitation, we propose DeepGEMM, a lookup table based approach for the execution of ultra low-precision convolutional neural networks on SIMD hardware. The proposed method precomputes all possible products of weights and activations, stores them in a lookup table, and efficiently accesses them at inference time to avoid costly multiply-accumulate operations. Our 2-bit implementation outperforms corresponding 8-bit integer kernels in the QNNPACK framework by up to 1.74x on x86 platforms.
@inproceedings{Ganji_2023_CVPR, author = {Ganji, Darshan C. and Ashfaq, Saad and Saboori, Ehsan and Sah, Sudhakar and Mitra, Saptarshi and AskariHemmat, MohammadHossein and Hoffman, Alexander and Hassanien, Ahmed and L\'eonardon, Mathieu}, title = {DeepGEMM: Accelerated Ultra Low-Precision Inference on CPU Architectures Using Lookup Tables}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops}, month = jun, year = {2023}, pages = {4655-4663}, }
2022
- DACAccelerating and Pruning CNNs for Semantic Segmentation on FPGAMorı̀, Pierpaolo, Vemparala, Manoj-Rohit, Fasfous, Nael, Mitra, Saptarshi, Sarkar, Sreetama, Frickenstein, Alexander, Frickenstein, Lukas, Helms, Domenik, Nagaraja, Naveen Shankar, Stechele, Walter, and Passerone, ClaudioIn Proceedings of the 59th ACM/IEEE Design Automation Conference Jun 2022
Semantic segmentation is one of the popular tasks in computer vision, providing pixel-wise annotations for scene understanding. However, segmentation-based convolutional neural networks require tremendous computational power. In this work, a fully-pipelined hardware accelerator with support for dilated convolution is introduced, which cuts down the redundant zero multiplications. Furthermore, we propose a genetic algorithm based automated channel pruning technique to jointly optimize computational complexity and model accuracy. Finally, hardware heuristics and an accurate model of the custom accelerator design enable a hardware-aware pruning framework. We achieve 2.44X lower latency with minimal degradation in semantic prediction quality (−1.98 pp lower mean intersection over union) compared to the baseline DeepLabV3+ model, evaluated on an Arria-10 FPGA. The binary files of the FPGA design, baseline and pruned models can be found in github.com/pierpaolomori/SemanticSegmentationFPGA
@inproceedings{10.1145/3489517.3530424, author = {Mor\`{\i}, Pierpaolo and Vemparala, Manoj-Rohit and Fasfous, Nael and Mitra, Saptarshi and Sarkar, Sreetama and Frickenstein, Alexander and Frickenstein, Lukas and Helms, Domenik and Nagaraja, Naveen Shankar and Stechele, Walter and Passerone, Claudio}, title = {Accelerating and Pruning CNNs for Semantic Segmentation on FPGA}, year = {2022}, isbn = {9781450391429}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3489517.3530424}, doi = {10.1145/3489517.3530424}, booktitle = {Proceedings of the 59th ACM/IEEE Design Automation Conference}, pages = {145–150}, numpages = {6}, location = {San Francisco, California}, series = {DAC '22}, }
2021
- Master ThesisAccelerating Semantic Image Segmentation on FPGAMitra, Saptarshi2021
From healthcare to autonomous driving, Deep Neural Networks (DNN) dominate over the traditional Computer Vision (CV) approaches in terms of accuracy and efficiency. Exponential increase of DNN applications require tremendous computation power of the underlying hardware resources. Naturally, the superior performance of DNN models comes at the cost of a huge memory footprint and complex calculations. Even if Graphics Processing Units (GPU) are the main work-horse during the training of DNNs for their massive computational capabilities, they are not suitable for mobile deployments. Field-programmable Gate Array (FPGA) provides the best trade-off between performance, power-consumption and design flexibility. Semantic image segmentation is one of the most complex tasks in computer vision, providing pixel-wise annotations for complete scene understanding. For a critical application like autonomous driving, DeepLabV3+ model provides the state-of-the-art Mean Intersection-Over-Union (mIOU) for semantic segmentation on the CityScapes dataset. In this work, a fully pipelined hardware accelerator implementing novel dilated convolution was introduced. Using this accelerator, an end-end DeepLabV3+ deployment was possible on an FPGA. This architecture exploits hardware optimizations like 3-D loop unrolling, memory tiling to maximize use of computational resources and provides 2.34 times latency improvement with respect to the baseline architecture. Further, a Genetic Algorithm (GA) based automated channel pruning technique was used to jointly optimize hardware usage and model accuracy. Finally, hardware awareness was incorporated in the pruning search by hardware heuristics and an accurate model of the custom accelerator.
author = {Mitra, Saptarshi}, booktitle = {Master's Thesis, Chair of Integrated Systems, Tecnical University of Munich}, title = {Accelerating Semantic Image Segmentation on FPGA}, year = {2021}, school = {Technische Universität München}, month = {}, adress = {81375 Munich}, pages = {}, language = {en}, keywords = {CNN; DNN; Semantic Segmentation; Hardware Acceleration; FPGA; HLS; OpenCL; Pruning}, note = {}, }
2018
-
 Implementation of relay hopper model for reliable communication of IoT devices in LTE environment through D2D linkIn 2018 10th International Conference on Communication Systems & Networks (COMSNETS) 2018
Implementation of relay hopper model for reliable communication of IoT devices in LTE environment through D2D linkIn 2018 10th International Conference on Communication Systems & Networks (COMSNETS) 2018Internet of things (IoT) is an emerging technology that can bring about a revolution in our day-to-day lives. Device- to-device (D2D) communication is an energy and spectral efficient solution to the growing problem of scarcity of free spectrum and overloading of base stations in cellular networks. The concept of using D2D communication in IoT networks has already been proposed. But the reliability of the links established by reusing the resource blocks allocated to licensed cellular users has not been investigated earlier. In this paper, our objective is to provide connectivity between IoT devices and the associated gateway using D2D communication ensuring that links established are reliable, and at the same time improve performance by providing connectivity to the maximum number of IoT devices. We propose a three step approach to achieve this. In the first step, the IoT devices satisfying the Quality of Service (QoS) constraint are selected and matched with appropriate reuse candidates, that is, the cellular user equipments (CUEs) by an optimum resource allocation scheme. Next, link reliability of these links are com- puted and weak links are discarded. Finally, the disconnected IoT devices are rerouted to the IoT gateway via IoT devices possessing strong links following a relay hopper model. Simulation results indicate significant improvement in the network performance metrics, namely, access rate and sum throughput of IoT devices.
@inproceedings{8328275, author = {Pradhan, Anish and Basu, Soumi and Sarkar, Sreetama and Mitra, Saptarshi and Roy, Sanjay Dhar}, booktitle = {2018 10th International Conference on Communication Systems & Networks (COMSNETS)}, title = {Implementation of relay hopper model for reliable communication of IoT devices in LTE environment through D2D link}, year = {2018}, volume = {}, number = {}, pages = {569-572}, doi = {10.1109/COMSNETS.2018.8328275}, }
2017
-
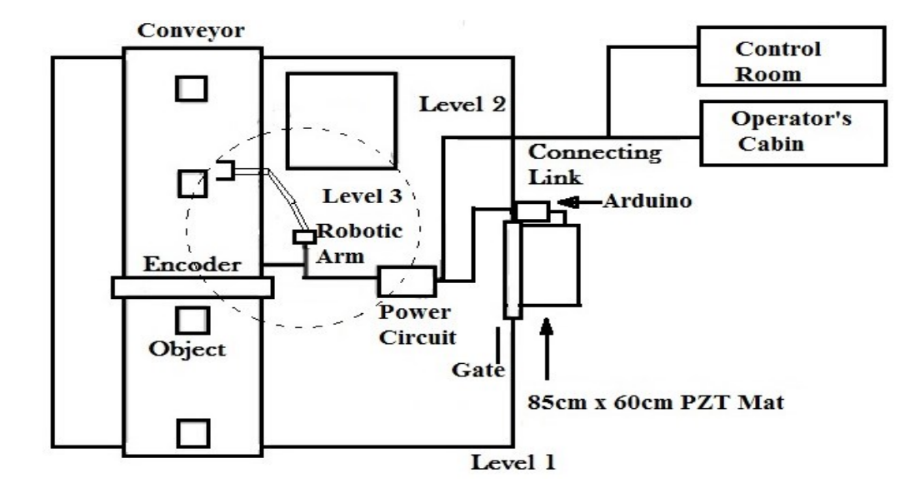 Arduino based foot pressure sensitive smart safety system for industrial robotsSarkar, Sayan, Ghosh, Gautam, Mohanta, Amitrakshar, Ghosh, Atreye, and Mitra, SaptarshiIn 2017 Second International Conference on Electrical, Computer and Communication Technologies (ICECCT) 2017
Arduino based foot pressure sensitive smart safety system for industrial robotsSarkar, Sayan, Ghosh, Gautam, Mohanta, Amitrakshar, Ghosh, Atreye, and Mitra, SaptarshiIn 2017 Second International Conference on Electrical, Computer and Communication Technologies (ICECCT) 2017Machine learning is one important aspect of automation. The research on automation raises a fundamental question: Can machines learn to act & behave like humans? Safe & efficient robot-human interaction - known as ‘collaborative robotics’ or ‘cobotics’ - has the power to transform production & assembly lines. The probability of industrial mishaps involving robots (like that in SKH metals, Manesar, August 2015) has increased with time. Companies using robots have burgeoned more safety programmes but they have some drawbacks. A real-time, MEMS sensor (PZT material) based, economical approach is proposed ensuring the safety in robotic workspace by shutting the robot system off or slowing it down upon human entry. During operation if a fault is detected at the robotic arm, the cabin operator is informed through the Human Machine Interface (HMI). The Arduino trips the robot when the operator steps on the piezoelectric mat (Doormat) while entering the workspace. The conventional safety switch can be bypassed since it is manual & sometimes problematic where fast response troubleshooting action is required but our proposed design has relatively less failure rate than traditional one. The unification of Arduino UNO & Relay, based on ‘OR’ logic protects the personnel from any unexpected robotic behaviour even when he fails to trigger the safety switch. The status of the robotic arm can be monitored distantly by IOT integration. It is programmed with a calculated threshold value of the foot pressure corresponding to 60 Kg of body mass for the circuit tripping to avoid false triggering. As this operation is part of a process plant, operators can increase the speed of other similar processes in the unit to compensate for the loss of production.
@inproceedings{8118009, author = {Sarkar, Sayan and Ghosh, Gautam and Mohanta, Amitrakshar and Ghosh, Atreye and Mitra, Saptarshi}, booktitle = {2017 Second International Conference on Electrical, Computer and Communication Technologies (ICECCT)}, title = {Arduino based foot pressure sensitive smart safety system for industrial robots}, year = {2017}, volume = {}, number = {}, pages = {1-6}, doi = {10.1109/ICECCT.2017.8118009}, } -
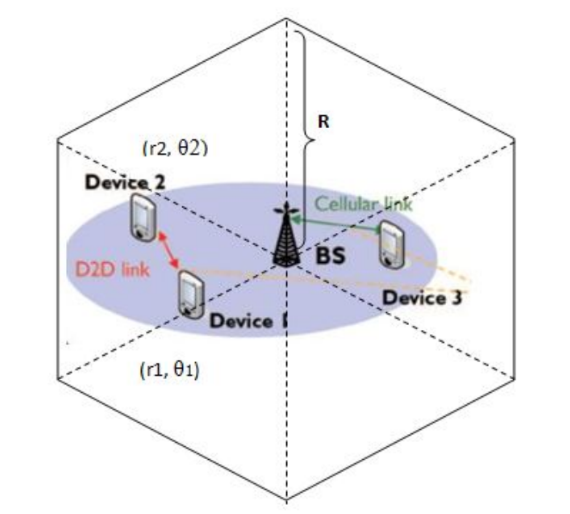 Performance of different power control schemes for a hybrid LTE system with channel impairmentIn 2017 International Electrical Engineering Congress (iEECON) 2017
Performance of different power control schemes for a hybrid LTE system with channel impairmentIn 2017 International Electrical Engineering Congress (iEECON) 2017With the rapid increase in the use of smartphones and data traffic load on the base stations increasing everyday, an alternative mode of communication is the need of the hour. Device-to-device (D2D) communication allows devices to connect to each other directly without the intervention of the base station. Besides, it provides high spectrum efficiency and a much better signal-to-interference-plus-noise ratio (SINR) performance as compared to cellular communication. However, it may generate significant interference to cellular users when the same resources are shared by both the systems. Resource scheduling and power control are two key measures to deal with the interference between cellular and D2D user equipment (UE). In this paper, we have focused mainly on power control in D2D communication. The main objective is to study the impact of channel imperfections like multipath fading and shadowing on different power control schemes. The system consisting of a D2D pair incorporated into an Orthogonal Frequency Division Multiple Access (OFDMA) cellular system is simulated for different combinations of power control schemes for cellular and D2D users. The variations in SINR performance of the system, when fading and shadowing are introduced in the channel along with pathloss, illustrates the effect of these parameters on the Long Term Evolution (LTE) power control schemes. Also the change in outage probability has been investigated by adding more D2D pairs to the system so that it resembles a D2D communication system in realtime scenario..
@inproceedings{8075838, author = {Sarkar, Sreetama and Mitra, Saptarshi and Nath, Tamoghno and Roy, Sanjay Dhar}, booktitle = {2017 International Electrical Engineering Congress (iEECON)}, title = {Performance of different power control schemes for a hybrid LTE system with channel impairment}, year = {2017}, volume = {}, number = {}, pages = {1-4}, doi = {10.1109/IEECON.2017.8075838}, }